Milestone¶
Abstract¶
Modern NLP models are typically evaluated by accuracy alone, despite substantial computational and energy costs, resulting in limited systematic understanding of how much of these resources is truly necessary to maintain competitive performance. In this project, we aim to characterize energy-accuracy tradeoffs using a controlled benchmarking framework with GPU power measurement, evaluating inference-time reductions including sequence truncation, numerical precision changes, and encoder depth variation. For a fine-tuned BERT-base model on SST-2 (\(\approx 93\%\) validation accuracy), we observe a wide flat region in the energy-accuracy Pareto frontier. Reducing maximum sequence length from \(128\) to \(48\) tokens and switching from FP32 to FP16 yield approximately \(12\times\) and \(4 \times\) energy reductions, respectively, without measurable loss in accuracy; combined, they provide an overall \(\approx 28\times\) reduction relative to the full baseline. In contrast, reducing encoder depth leads to rapid accuracy degradation. These results show that substantial inference-time energy savings are achievable without sacrificing performance, while different forms of model redundancy produce qualitatively distinct efficiency tradeoffs.
Approach¶
Model and baseline¶
Prior work has demonstrated substantial redundancy in pretrained models, including sparse subnetworks that match full-model accuracy1. Building on this, we study energy-accuracy tradeoffs in pretrained Transformer models by holding the downstream task, initialization, and fine-tuning protocol fixed while varying inference-time computation.
Our primary experimental platform is BERT-base2, implemented using the Hugging Face Transformers library. . Pretrained weights are treated as a fixed initialization, and we perform standard full fine-tuning without architectural modifications. The baseline consists of the fully fine-tuned model evaluated at full numerical precision and full encoder depth. BERT-base achieves approximately \(93-94\%\) accuracy on SST-22, providing a competitive reference point.
Inference-time reduction axes¶
Our methodology is comparative rather than algorithmic. We evaluate three orthogonal inference-time axes: (i) sequence length truncation via fixed maximum token limits, (ii) encoder depth variation by retaining the first \(k\) layers34, and (iii) reduced floating-point precision at inference.
These static, deployment-compatible reductions require no retraining and isolate computational effects while holding model weights fixed. Unlike adaptive approaches such as token pruning or early exit, they enable controlled, axis-aligned comparisons.
Measurement framework¶
Our contribution is a controlled benchmarking framework for comparing efficiency strategies under identical conditions. All configurations are evaluated using a unified inference harness implemented by us. Latency is measured via synchronized wall-clock timing, and energy (\(E\)) is computed by integrating instantaneous GPU power (\(P(t)\)) over total inference time (\(T\)):
Each configuration is evaluated on a fixed number of batches following a warm-up phase. For every reduction axis, we construct empirical energy-accuracy and energy-latency Pareto frontiers to identify non-dominated configurations.
Experiments¶
Data and task¶
We conduct experiments on the Stanford Sentiment Treebank (SST-2) dataset, a binary sentence-level sentiment classification task from GLUE5. SST-2 contains approximately 67,000 labeled sentences with standard train and validation splits. The task consists of predicting positive or negative sentiment for a single input sentence. We report results on the official validation split.
Evaluation metrics¶
We report accuracy and efficiency metrics: energy per example (J/example), energy per correct prediction (J/correct prediction), average latency per example (ms), and peak GPU memory usage (MB). Energy and latency are measured as described in the Measure framework section under identical hardware and software conditions.
Experimental setup¶
Experiments run on a single NVIDIA L4 GPU using PyTorch with CUDA support. We fine-tune BERT-base2 for two epochs with a learning rate of \(3 \times 10^{-5}\), a batch size of \(32\) for training and \(64\) for evaluation, a weight decay of \(0.01\), and a warmup ratio of \(0.06\), reaching approximately \(93\%\) validation accuracy. We evaluate sequence length truncation (\(16\)–\(128\) tokens), encoder depth variation (\(2\)–\(12\) layers), and numerical precision reduction (FP32 vs. FP16), constructing empirical energy–accuracy and energy-latency Pareto frontiers.
Results¶
The fully fine-tuned baseline (\(128\) tokens, full depth, FP32) consumes approximately \(0.23\) J/example at \(\approx 93\%\) accuracy.
Sequence length truncation exhibits a wide flat region in the accuracy–energy frontier (Figure 1): reducing from \(128\) to \(48\) tokens decreases energy by approximately \(12 \times\) at unchanged accuracy. Below \(48\) tokens, accuracy degrades progressively. Latency decreases approximately linearly with sequence length.
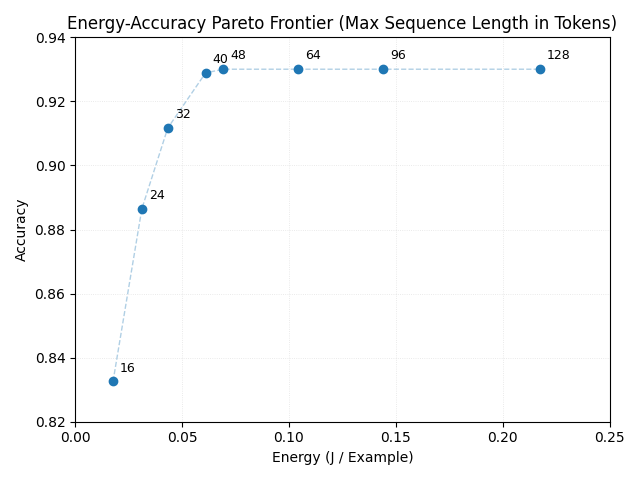 Figure 1: Energy-Accuracy Pareto Frontier (Max Sequence Length in Tokens).
Figure 1: Energy-Accuracy Pareto Frontier (Max Sequence Length in Tokens).
Numerical precision reduction from FP32 to FP16 decreases energy consumption by \(\approx 4 \times\) without measurable accuracy loss (Figure 2).
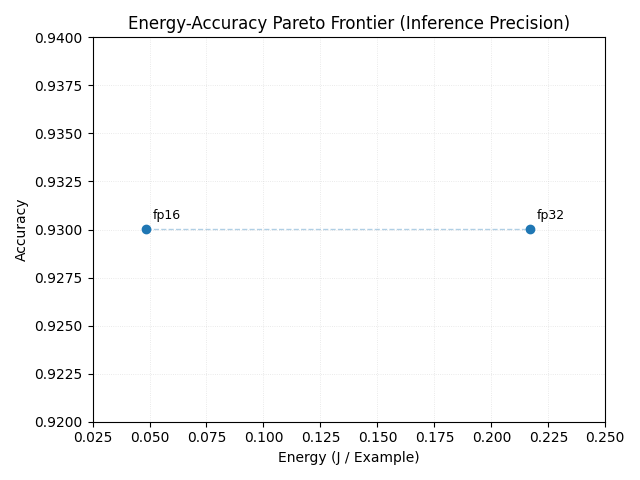 Figure 2: Energy-Accuracy Pareto Frontier (Inference Precision).
Figure 2: Energy-Accuracy Pareto Frontier (Inference Precision).
In contrast, encoder depth variation leads to rapid and monotonic accuracy degradation (Figure 3), indicating that depth is less redundant than input length or arithmetic precision in this task.
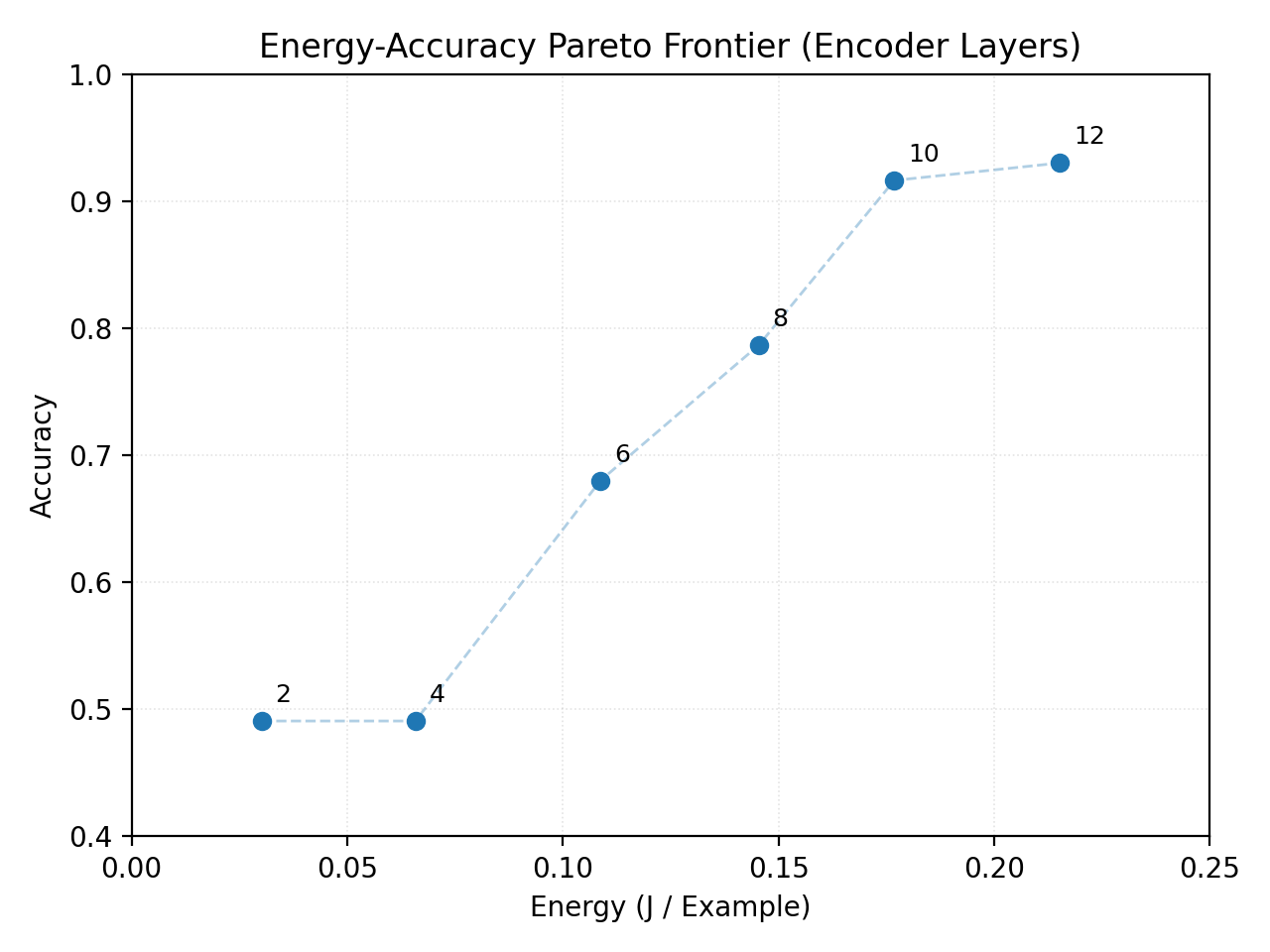 Figure 3: Energy-Accuracy Pareto Frontier (Encoder Layers).
Figure 3: Energy-Accuracy Pareto Frontier (Encoder Layers).
Combined reduction of precision (FP16) and sequence length (\(48\) tokens) results in approximately \(28 \times\) lower energy consumption relative to the full baseline while preserving accuracy (Figure 4).
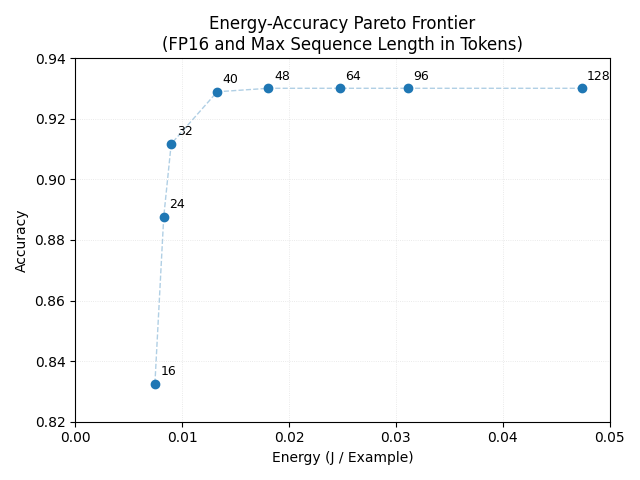 Figure 4: Energy-Accuracy Pareto Frontier (FP16 and Max Sequence Length in Tokens).
Figure 4: Energy-Accuracy Pareto Frontier (FP16 and Max Sequence Length in Tokens).
Within the stable accuracy regime, energy scales approximately linearly with maximum sequence length and multiplicatively with numerical precision, suggesting a simple, axis-aligned structure in the observed Pareto frontier.
Future work¶
We will extend our analysis to Quora Question Pairs (QQP) to assess whether the efficiency-accuracy trends observed on SST-2 generalize to longer, paired inputs. As a stretch goal, we will evaluate SQuAD v1.1 to characterize tradeoffs in extractive question answering with longer contexts. These extensions will enable a direct examination of task dependence under a unified measurement framework.
To improve robustness, we will repeat key experiments with multiple random seeds and average energy measurements across runs. We will also explore simple empirical fits within the stable accuracy regime to determine whether the observed Pareto frontiers admit compact interpolation models.
References¶
-
Tianlong Chen, Jonathan Frankle, Shiyu Chang, Sijia Liu, Yang Zhang, Zhangyang Wang, and Michael Carbin. The lottery ticket hypothesis for pre-trained bert networks. In Proceedings of the 34th International Conference on Neural Information Processing Systems (NeurIPS 20), pages 15834–15846, 2020. ↩
-
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL-HLT 2019), pages 4171–4186, 2019. ↩↩↩
-
Paul Michel, Omer Levy, and Graham Neubig. Are sixteen heads really better than one? In Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS 19), pages 14037–14047, 2019. ↩
-
Elena Voita, David Talbot, Fedor Moiseev, Rico Sennrich, and Ivan Titov. Analyzing multi-head self-attention: Specialized heads do the heavy lifting, the rest can be pruned. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL 2019), pages 5797–5808, 2019. ↩
-
Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bowman. Glue: A multi-task benchmark and analysis platform for natural language understanding. In Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, pages 353–355, 2018. ↩